# 버퍼와 인덱스
# 드디어 그것들에 대해 이야기할 시간입니다!
제가 "버퍼에 대해 이야기할 때 다루겠습니다" 같은 말을 반복하는 것에 아마 질리셨을 겁니다. 자, 이제 드디어 버퍼에 대해 이야기할 시간이지만, 그 전에 먼저...
# 버퍼란 무엇일까요?
버퍼는 GPU에 있는 데이터 덩어리(blob)입니다. 버퍼는 모든 데이터가 메모리 상에 순차적으로 저장되는 **연속성(contiguous)**이 보장됩니다. 버퍼는 일반적으로 구조체나 배열과 같은 간단한 것들을 저장하는 데 사용되지만, 트리와 같은 그래프 구조와 같은 더 복잡한 것들도 저장할 수 있습니다(단, 모든 노드가 함께 저장되고 버퍼 외부의 어떤 것도 참조하지 않는 경우에 한합니다). 우리는 버퍼를 많이 사용할 것이므로, 가장 중요한 두 가지인 정점 버퍼와 인덱스 버퍼부터 시작해 봅시다.
# 정점 버퍼
이전에는 정점 데이터를 정점 셰이더에 직접 저장했습니다. 이 방법은 처음 시작하기에는 괜찮았지만, 장기적으로는 적합하지 않습니다. 우리가 그려야 할 객체의 종류는 is_surface_configured: false에서 다양하게 변할 수 있으며, 모델을 업데이트할 때마다 셰이더를 다시 컴파일하는 것은 프로그램 속도를 엄청나게 저하시킬 것입니다. 대신, 우리는 버퍼를 사용하여 그리고자 하는 정점 데이터를 저장할 것입니다. 하지만 그 전에, 정점이 어떻게 생겼는지 설명해야 합니다. 이를 위해 새로운 구조체를 만들겠습니다.
// lib.rs
#[repr(C)]
#[derive(Copy, Clone, Debug)]
struct Vertex {
position: [f32; 3],
color: [f32; 3],
}
우리의 모든 정점은 위치(position)와 색상(color)을 가집니다. 위치는 3D 공간에서의 정점의 x, y, z 좌표를 나타냅니다. 색상은 정점의 빨강, 초록, 파랑 값을 나타냅니다. Vertex가 Copy 트레이트를 구현해야 이로부터 버퍼를 만들 수 있습니다.
다음으로, 삼각형을 구성할 실제 데이터가 필요합니다. Vertex 구조체 아래에 다음을 추가하세요.
// lib.rs
const VERTICES: &[Vertex] = &[
Vertex { position: [0.0, 0.5, 0.0], color: [1.0, 0.0, 0.0] },
Vertex { position: [-0.5, -0.5, 0.0], color: [0.0, 1.0, 0.0] },
Vertex { position: [0.5, -0.5, 0.0], color: [0.0, 0.0, 1.0] },
];
정점을 반시계 방향(위, 왼쪽 아래, 오른쪽 아래)으로 배열합니다. 이렇게 하는 이유는 부분적으로는 전통 때문이기도 하지만, 주로 render_pipeline의 primitive에서 삼각형의 front_face(앞면)를 wgpu::FrontFace::Ccw로 지정하여 뒷면을 컬링(cull)하도록 했기 때문입니다. 이는 우리를 향해야 하는 모든 삼각형의 정점이 반시계 방향으로 배열되어야 함을 의미합니다.
이제 정점 데이터가 준비되었으니, 이를 버퍼에 저장해야 합니다. State에 vertex_buffer 필드를 추가합시다.
// lib.rs
pub struct State {
// ...
render_pipeline: wgpu::RenderPipeline,
// 새로운 코드!
vertex_buffer: wgpu::Buffer,
// ...
}
이제 new()에서 버퍼를 생성해 봅시다.
// new()
let vertex_buffer = device.create_buffer_init(
&wgpu::util::BufferInitDescriptor {
label: Some("Vertex Buffer"),
contents: bytemuck::cast_slice(VERTICES),
usage: wgpu::BufferUsages::VERTEX,
}
);
wgpu::Device에서 create_buffer_init 메서드에 접근하려면, DeviceExt (opens new window) 확장 트레이트(extension trait)를 가져와야 합니다. 확장 트레이트에 대한 더 자세한 정보는 이 글 (opens new window)을 확인하세요.
확장 트레이트를 가져오려면 lib.rs 상단 어딘가에 이 줄을 추가하세요.
use wgpu::util::DeviceExt;
VERTICES를 &[u8]로 캐스팅하기 위해 bytemuck (opens new window)을 사용하고 있음을 알 수 있습니다. create_buffer_init() 메서드는 &[u8]를 받으며, bytemuck::cast_slice가 이 작업을 해줍니다. Cargo.toml에 다음을 추가하세요.
bytemuck = { version = "1.16", features = [ "derive" ] }
또한 bytemuck이 작동하게 하려면 두 개의 트레이트를 구현해야 합니다. 이들은 bytemuck::Pod (opens new window)와 bytemuck::Zeroable (opens new window)입니다. Pod는 우리 Vertex가 "Plain Old Data"임을 나타내며, 따라서 &[u8]로 해석될 수 있음을 의미합니다. Zeroable은 std::mem::zeroed()를 사용할 수 있음을 나타냅니다. Vertex 구조체를 수정하여 이 메서드들을 derive 할 수 있습니다.
#[repr(C)]
#[derive(Copy, Clone, Debug, bytemuck::Pod, bytemuck::Zeroable)]
struct Vertex {
position: [f32; 3],
color: [f32; 3],
}
만약 구조체에 Pod와 Zeroable을 구현하지 않는 타입이 포함되어 있다면, 이 트레이트들을 수동으로 구현해야 합니다. 이 트레이트들은 우리가 어떤 메서드도 구현할 것을 요구하지 않으므로, 코드가 작동하게 하려면 다음을 사용하면 됩니다.
unsafe impl bytemuck::Pod for Vertex {}
unsafe impl bytemuck::Zeroable for Vertex {}
마지막으로, vertex_buffer를 State 구조체에 추가할 수 있습니다.
Ok(Self {
surface,
device,
queue,
config,
is_surface_configured: false,
window,
render_pipeline,
vertex_buffer,
})
# 그래서, 이걸로 뭘 해야 할까요?
그리기 작업을 할 때 render_pipeline에게 이 버퍼를 사용하라고 알려줘야 하지만, 그 전에 render_pipeline에게 버퍼를 어떻게 읽어야 하는지 알려줘야 합니다. 이 작업은 VertexBufferLayout과 render_pipeline을 만들 때 이야기하겠다고 약속했던 vertex_buffers 필드를 사용하여 수행합니다.
VertexBufferLayout은 버퍼가 메모리에서 어떻게 표현되는지를 정의합니다. 이것이 없으면 render_pipeline은 셰이더에서 버퍼를 어떻게 매핑해야 할지 알 수 없습니다. Vertex로 가득 찬 버퍼에 대한 디스크립터(descriptor)는 다음과 같습니다.
wgpu::VertexBufferLayout {
array_stride: std::mem::size_of::<Vertex>() as wgpu::BufferAddress, // 1.
step_mode: wgpu::VertexStepMode::Vertex, // 2.
attributes: &[ // 3.
wgpu::VertexAttribute {
offset: 0, // 4.
shader_location: 0, // 5.
format: wgpu::VertexFormat::Float32x3, // 6.
},
wgpu::VertexAttribute {
offset: std::mem::size_of::<[f32; 3]>() as wgpu::BufferAddress,
shader_location: 1,
format: wgpu::VertexFormat::Float32x3,
}
]
}
array_stride는 정점 하나의 크기가 얼마인지를 정의합니다. 셰이더가 다음 정점을 읽으러 갈 때,array_stride만큼의 바이트를 건너뛸 것입니다. 우리 경우,array_stride는 아마 24바이트일 것입니다.step_mode는 이 버퍼에 있는 배열의 각 요소가 정점별(per-vertex) 데이터를 나타내는지, 인스턴스별(per-instance) 데이터를 나타내는지를 파이프라인에 알려줍니다. 만약 새로운 인스턴스를 그리기 시작할 때만 정점을 바꾸고 싶다면wgpu::VertexStepMode::Instance를 지정할 수 있습니다. 인스턴싱은 나중 튜토리얼에서 다룰 것입니다.attributes(속성)는 정점의 개별 부분을 설명합니다. 일반적으로 이는 구조체의 필드와 1:1로 매핑되며, 우리 경우도 마찬가지입니다.offset은 속성이 시작되기까지의 바이트 단위 오프셋을 정의합니다. 첫 번째 속성의 경우, 오프셋은 보통 0입니다. 이후 속성들의 오프셋은 이전 속성들의 데이터 크기(size_of)의 총합입니다.shader_location은 이 속성을 어느 위치에 저장할지를 셰이더에 알려줍니다. 예를 들어, 정점 셰이더의@location(0) x: vec3<f32>는Vertex구조체의position필드에 해당하고,@location(1) x: vec3<f32>는color필드에 해당합니다.format은 속성의 형태를 셰이더에 알려줍니다.Float32x3은 셰이더 코드의vec3<f32>에 해당합니다. 속성에 저장할 수 있는 최대값은Float32x4입니다(Uint32x4,Sint32x4도 가능).Float32x4보다 큰 것을 저장해야 할 때 이를 염두에 둘 것입니다.
시각적인 학습자를 위해, 우리의 정점 버퍼는 다음과 같이 보입니다.
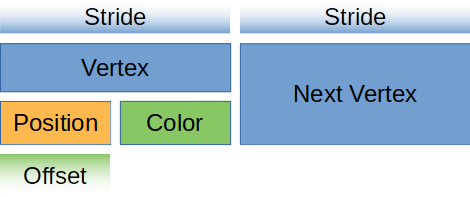
Vertex에 이 디스크립터를 반환하는 정적 메서드를 만들어 봅시다.
// lib.rs
impl Vertex {
fn desc() -> wgpu::VertexBufferLayout<'static> {
wgpu::VertexBufferLayout {
array_stride: std::mem::size_of::<Vertex>() as wgpu::BufferAddress,
step_mode: wgpu::VertexStepMode::Vertex,
attributes: &[
wgpu::VertexAttribute {
offset: 0,
shader_location: 0,
format: wgpu::VertexFormat::Float32x3,
},
wgpu::VertexAttribute {
offset: std::mem::size_of::<[f32; 3]>() as wgpu::BufferAddress,
shader_location: 1,
format: wgpu::VertexFormat::Float32x3,
}
]
}
}
}
지금처럼 속성을 지정하는 것은 꽤 장황합니다. wgpu에서 제공하는 vertex_attr_array 매크로를 사용하면 코드를 좀 더 깔끔하게 만들 수 있습니다. 이를 사용하면 VertexBufferLayout은 다음과 같이 됩니다.
wgpu::VertexBufferLayout {
array_stride: std::mem::size_of::<Vertex>() as wgpu::BufferAddress,
step_mode: wgpu::VertexStepMode::Vertex,
attributes: &wgpu::vertex_attr_array![0 => Float32x3, 1 => Float32x3],
}
이것이 확실히 좋긴 하지만, Rust는 vertex_attr_array의 결과를 임시 값으로 보기 때문에 함수에서 반환하려면 약간의 수정이 필요합니다. 아래 예제처럼 const로 만들 수 있습니다 (opens new window).
impl Vertex {
const ATTRIBS: [wgpu::VertexAttribute; 2] =
wgpu::vertex_attr_array![0 => Float32x3, 1 => Float32x3];
fn desc() -> wgpu::VertexBufferLayout<'static> {
use std::mem;
wgpu::VertexBufferLayout {
array_stride: mem::size_of::<Self>() as wgpu::BufferAddress,
step_mode: wgpu::VertexStepMode::Vertex,
attributes: &Self::ATTRIBS,
}
}
}
어쨌든, 데이터가 어떻게 매핑되는지 보여주는 것이 좋다고 생각하므로, 지금은 이 매크로를 사용하지 않겠습니다.
이제, render_pipeline을 만들 때 이것을 사용할 수 있습니다.
let render_pipeline = device.create_render_pipeline(&wgpu::RenderPipelineDescriptor {
// ...
vertex: wgpu::VertexState {
// ...
buffers: &[
Vertex::desc(),
],
},
// ...
});
한 가지 더: 렌더 메서드에서 실제로 정점 버퍼를 설정해야 합니다. 그렇지 않으면 프로그램이 충돌할 것입니다.
// render()
render_pass.set_pipeline(&self.render_pipeline);
// 새로운 코드!
render_pass.set_vertex_buffer(0, self.vertex_buffer.slice(..));
render_pass.draw(0..3, 0..1);
set_vertex_buffer는 두 개의 매개변수를 받습니다. 첫 번째는 이 정점 버퍼에 사용할 버퍼 슬롯입니다. 한 번에 여러 개의 정점 버퍼를 설정할 수 있습니다.
두 번째 매개변수는 사용할 버퍼의 슬라이스입니다. 하드웨어가 허용하는 한 버퍼에 많은 객체를 저장할 수 있으므로, slice를 사용하면 사용할 버퍼의 부분을 지정할 수 있습니다. ..를 사용하여 전체 버퍼를 지정합니다.
계속하기 전에, render_pass.draw() 호출이 VERTICES에 지정된 정점 수를 사용하도록 변경해야 합니다. State에 num_vertices를 추가하고, VERTICES.len()과 같게 설정하세요.
// lib.rs
pub struct State {
// ...
num_vertices: u32,
}
impl State {
// ...
fn new(...) -> Self {
// ...
let num_vertices = VERTICES.len() as u32;
Self {
surface,
device,
queue,
config,
is_surface_configured: false,
window,
render_pipeline,
vertex_buffer,
num_vertices,
}
}
}
그런 다음, draw 호출에서 사용하세요.
// render
render_pass.draw(0..self.num_vertices, 0..1);
우리의 변경 사항이 효과를 발휘하려면, 정점 셰이더가 정점 버퍼에서 데이터를 가져오도록 업데이트해야 합니다. 또한 정점 색상도 포함하도록 할 것입니다.
// Vertex shader
struct VertexInput {
@location(0) position: vec3<f32>,
@location(1) color: vec3<f32>,
};
struct VertexOutput {
@builtin(position) clip_position: vec4<f32>,
@location(0) color: vec3<f32>,
};
@vertex
fn vs_main(
model: VertexInput,
) -> VertexOutput {
var out: VertexOutput;
out.color = model.color;
out.clip_position = vec4<f32>(model.position, 1.0);
return out;
}
// Fragment shader
@fragment
fn fs_main(in: VertexOutput) -> @location(0) vec4<f32> {
return vec4<f32>(in.color, 1.0);
}
모든 것을 올바르게 했다면, 다음과 같이 생긴 삼각형이 보일 것입니다.
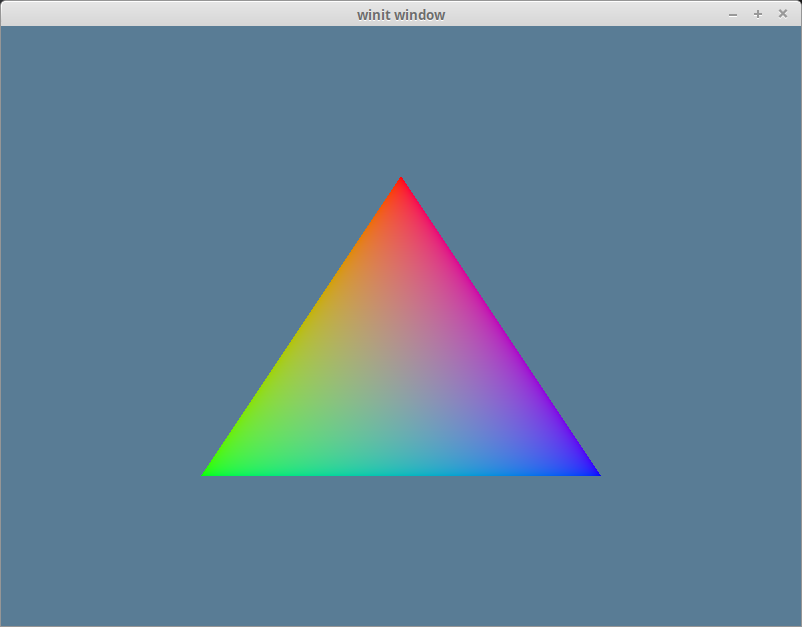
# 인덱스 버퍼
기술적으로 인덱스 버퍼가 필수는 아니지만, 여전히 매우 유용합니다. 인덱스 버퍼는 많은 삼각형으로 이루어진 모델을 사용하기 시작할 때 중요해집니다. 이 오각형을 생각해 보세요.
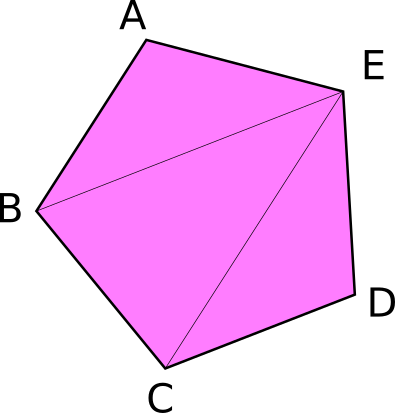
총 5개의 정점과 3개의 삼각형으로 이루어져 있습니다. 이제, 만약 이런 것을 정점만 사용해서 표시하고 싶다면, 다음과 같은 것이 필요할 것입니다.
const VERTICES: &[Vertex] = &[
Vertex { position: [-0.0868241, 0.49240386, 0.0], color: [0.5, 0.0, 0.5] }, // A
Vertex { position: [-0.49513406, 0.06958647, 0.0], color: [0.5, 0.0, 0.5] }, // B
Vertex { position: [0.44147372, 0.2347359, 0.0], color: [0.5, 0.0, 0.5] }, // E
Vertex { position: [-0.49513406, 0.06958647, 0.0], color: [0.5, 0.0, 0.5] }, // B
Vertex { position: [-0.21918549, -0.44939706, 0.0], color: [0.5, 0.0, 0.5] }, // C
Vertex { position: [0.44147372, 0.2347359, 0.0], color: [0.5, 0.0, 0.5] }, // E
Vertex { position: [-0.21918549, -0.44939706, 0.0], color: [0.5, 0.0, 0.5] }, // C
Vertex { position: [0.35966998, -0.3473291, 0.0], color: [0.5, 0.0, 0.5] }, // D
Vertex { position: [0.44147372, 0.2347359, 0.0], color: [0.5, 0.0, 0.5] }, // E
];
하지만 일부 정점은 두 번 이상 사용되는 것을 알 수 있습니다. C와 B는 두 번 사용되고, E는 세 번 반복됩니다. 각 float가 4바이트라고 가정하면, VERTICES에 사용하는 216바이트 중 96바이트가 중복 데이터라는 의미입니다. 이 정점들을 한 번만 나열할 수 있다면 좋지 않을까요? 네, 할 수 있습니다! 바로 여기서 인덱스 버퍼가 사용됩니다.
기본적으로, 모든 고유한 정점을 VERTICES에 저장하고, VERTICES의 요소에 대한 인덱스를 저장하는 다른 버퍼를 만들어 삼각형을 생성합니다. 오각형을 예로 들면 다음과 같습니다.
// lib.rs
const VERTICES: &[Vertex] = &[
Vertex { position: [-0.0868241, 0.49240386, 0.0], color: [0.5, 0.0, 0.5] }, // A
Vertex { position: [-0.49513406, 0.06958647, 0.0], color: [0.5, 0.0, 0.5] }, // B
Vertex { position: [-0.21918549, -0.44939706, 0.0], color: [0.5, 0.0, 0.5] }, // C
Vertex { position: [0.35966998, -0.3473291, 0.0], color: [0.5, 0.0, 0.5] }, // D
Vertex { position: [0.44147372, 0.2347359, 0.0], color: [0.5, 0.0, 0.5] }, // E
];
const INDICES: &[u16] = &[
0, 1, 4,
1, 2, 4,
2, 3, 4,
];
이제 이 설정으로, VERTICES는 약 120바이트를 차지하고 INDICES는 u16이 2바이트이므로 단 18바이트입니다. 이 경우, wgpu는 버퍼가 4바이트에 정렬되도록 자동으로 2바이트의 패딩을 추가하지만, 그래도 여전히 20바이트에 불과합니다. 모두 합쳐서 우리 오각형은 총 140바이트입니다. 이는 76바이트를 절약했다는 의미입니다! 많아 보이지 않을 수 있지만, 수십만 개의 삼각형을 다룰 때 인덱싱은 많은 메모리를 절약해 줍니다. 인덱스의 순서가 중요하다는 점에 유의하세요. 위 예제에서 삼각형은 반시계 방향으로 생성됩니다. 만약 시계 방향으로 바꾸고 싶다면, 렌더 파이프라인으로 가서 front_face를 Cw로 변경하세요.
인덱싱을 사용하기 위해 변경해야 할 몇 가지 사항이 있습니다. 첫 번째는 인덱스를 저장할 버퍼를 만드는 것입니다. State의 new() 메서드에서 vertex_buffer를 만든 후에 index_buffer를 만드세요. 또한 num_vertices를 num_indices로 변경하고 INDICES.len()과 같게 설정하세요.
let vertex_buffer = device.create_buffer_init(
&wgpu::util::BufferInitDescriptor {
label: Some("Vertex Buffer"),
contents: bytemuck::cast_slice(VERTICES),
usage: wgpu::BufferUsages::VERTEX,
}
);
// 새로운 코드!
let index_buffer = device.create_buffer_init(
&wgpu::util::BufferInitDescriptor {
label: Some("Index Buffer"),
contents: bytemuck::cast_slice(INDICES),
usage: wgpu::BufferUsages::INDEX,
}
);
let num_indices = INDICES.len() as u32;
인덱스에 대해서는 Pod와 Zeroable을 구현할 필요가 없습니다. 왜냐하면 bytemuck이 u16과 같은 기본 타입에 대해 이미 구현해 놓았기 때문입니다. 즉, State 구조체에 index_buffer와 num_indices를 추가하기만 하면 됩니다.
pub struct State {
surface: wgpu::Surface<'static>,
device: wgpu::Device,
queue: wgpu::Queue,
config: wgpu::SurfaceConfiguration,
is_surface_configured: bool,
window: Arc<Window>,
render_pipeline: wgpu::RenderPipeline,
vertex_buffer: wgpu::Buffer,
// 새로운 코드!
index_buffer: wgpu::Buffer,
num_indices: u32,
}
그런 다음 생성자에서 이 필드들을 채워줍니다:
Ok(Self {
surface,
device,
queue,
config,
is_surface_configured: false,
window,
render_pipeline,
vertex_buffer,
// 새로운 코드!
index_buffer,
num_indices,
})
이제 남은 일은 render() 메서드를 업데이트하여 index_buffer를 사용하는 것뿐입니다.
// render()
render_pass.set_pipeline(&self.render_pipeline);
render_pass.set_vertex_buffer(0, self.vertex_buffer.slice(..));
render_pass.set_index_buffer(self.index_buffer.slice(..), wgpu::IndexFormat::Uint16); // 1.
render_pass.draw_indexed(0..self.num_indices, 0, 0..1); // 2.
몇 가지 주의할 점:
- 메서드 이름은
set_index_buffer이지,set_index_buffers가 아닙니다. 한 번에 하나의 인덱스 버퍼만 설정할 수 있습니다. - 인덱스 버퍼를 사용할 때는
draw_indexed를 사용해야 합니다.draw메서드는 인덱스 버퍼를 무시합니다. 또한, 모델이 잘못 그려지거나 인덱스가 부족하여 메서드가panic을 일으키지 않도록 정점 수(num_vertices)가 아닌 인덱스 수(num_indices)를 사용해야 합니다.
이 모든 것을 마치면 창에 화려한 자홍색 오각형이 나타날 것입니다.

# 색상 보정
자홍색 오각형에 색상 선택기(color picker)를 사용하면 #BC00BC라는 16진수 값을 얻게 됩니다. 이를 RGB 값으로 변환하면 (188, 0, 188)이 됩니다. 이 값들을 255로 나누어 [0, 1] 범위로 만들면 대략 (0.737254902, 0, 0.737254902)가 됩니다. 이는 우리가 정점 색상으로 사용하고 있는 (0.5, 0.0, 0.5)와 다릅니다. 그 이유는 색 공간(color space)과 관련이 있습니다.
대부분의 모니터는 sRGB라는 색 공간을 사용합니다. 우리 서피스는 (아마도 surface.get_preferred_format()이 반환하는 값에 따라) sRGB 텍스처 형식을 사용하고 있습니다. sRGB 형식은 색상을 실제 밝기가 아닌 상대적인 밝기에 따라 저장합니다. 그 이유는 우리 눈이 빛을 선형적으로 인식하지 않기 때문입니다. 우리는 밝은 색보다 어두운 색에서 더 많은 차이를 알아챕니다.
색상을 사용하는 대부분의 소프트웨어는 sRGB 형식(또는 유사한 독점 형식)으로 색상을 저장합니다. wgpu는 선형 색 공간(linear color space)의 값을 기대하므로 값을 변환해야 합니다.
다음 공식을 사용하여 올바른 색상을 얻을 수 있습니다: rgb_color = ((srgb_color / 255 + 0.055) / 1.055) ^ 2.4. sRGB 값 (188, 0, 188)에 이 공식을 적용하면 (0.5028864580325687, 0.0, 0.5028864580325687)이 나옵니다. 우리의 (0.5, 0.0, 0.5)와는 약간 다릅니다. 수동으로 색상 변환을 하는 대신, 텍스처를 사용하면 시간을 많이 절약할 수 있습니다. 텍스처가 sRGB 텍스처에 저장되어 있다면 선형으로의 변환이 자동으로 일어나기 때문입니다. 텍스처는 다음 강의에서 다룰 것입니다.
# 데모
# 도전 과제
우리가 만든 것보다 더 복잡한 모양(즉, 세 개 이상의 삼각형)을 정점 버퍼와 인덱스 버퍼를 사용하여 만들어 보세요. 스페이스 키를 눌러 두 가지를 번갈아 가며 표시해 보세요.
← 파이프라인 텍스처와 바인드 그룹 →