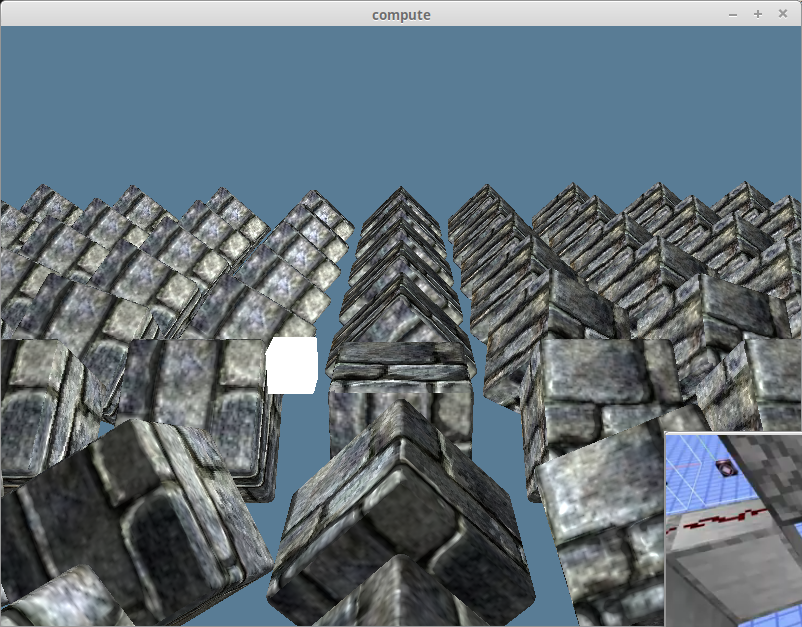
# 컴퓨트 예제: 탄젠트와 바이탄젠트 계산
이 작업은 예상보다 더 까다로웠습니다. 제가 처음 마주한 문제는 셰이더가 정점 데이터를 잘못 읽어 데이터가 손상되는 것이었습니다. 저는 노멀 매핑 튜토리얼에서 사용했던 ModelVertex 구조체를 사용하고 있었습니다.
#[repr(C)]
#[derive(Copy, Clone, Debug, bytemuck::Pod, bytemuck::Zeroable)]
pub struct ModelVertex {
position: [f32; 3],
tex_coords: [f32; 2],
normal: [f32; 3],
tangent: [f32; 3],
bitangent: [f32; 3],
}
이 구조체는 정점 버퍼(vertex buffer)로 사용할 때는 전혀 문제가 없었지만, 스토리지 버퍼(storage buffer)로 사용하기에는 불편함이 있었습니다. 이전 코드에서는 제 ModelVertex와 유사한 GLSL 구조체를 사용했습니다.
struct ModelVertex {
vec3 position;
vec2 tex_coords;
vec3 normal;
vec3 tangent;
vec3 bitangent;
};
얼핏 보면 괜찮아 보이지만, OpenGL 전문가라면 이 구조체에서 문제를 발견했을 것입니다. 필드들이 스토리지 버퍼가 요구하는 std430 정렬(alignment)을 지원하도록 제대로 정렬되어 있지 않기 때문입니다. 자세한 내용은 다루지 않겠지만, 더 자세히 알고 싶으시다면 정렬 쇼케이스를 확인해 보세요. 요약하자면, tex_coords의 vec2가 바이트 정렬을 망가뜨려 정점 데이터를 손상시켰고, 그 결과는 다음과 같았습니다:
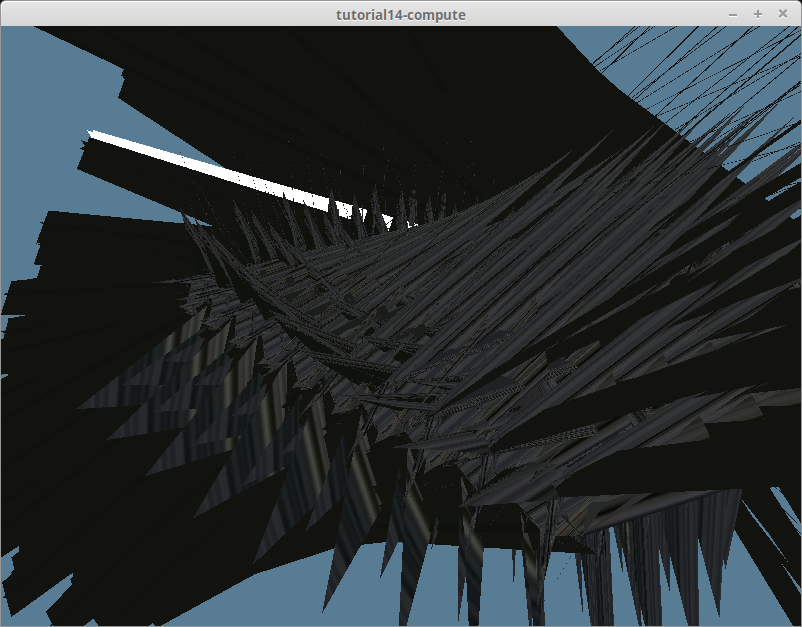
Rust 쪽에서 tex_coords 뒤에 패딩(padding) 필드를 추가하여 이 문제를 해결할 수도 있었지만, 그러려면 VertexBufferLayout을 수정해야 했습니다. 결국 저는 벡터의 각 요소를 직접 사용하여 이 문제를 해결했고, 그 결과 다음과 같은 구조체가 되었습니다:
struct ModelVertex {
float x; float y; float z;
float uv; float uw;
float nx; float ny; float nz;
float tx; float ty; float tz;
float bx; float by; float bz;
};
std430은 구조체에서 가장 큰 요소의 정렬을 사용하므로, 모두 float을 사용하면 구조체는 4바이트로 정렬됩니다. 이 정렬 방식은 Rust의 ModelVertex가 사용하는 방식과 일치합니다. 작업하기에는 다소 번거로웠지만, 데이터 손상 문제는 해결되었습니다.
두 번째 문제는 탄젠트와 바이탄젠트를 계산하는 방식을 재고하게 만들었습니다. 이전에 사용하던 알고리즘은 각 삼각형에 대한 탄젠트와 바이탄젠트만 계산하고, 해당 삼각형의 모든 정점이 동일한 탄젠트와 바이탄젠트를 사용하도록 설정했습니다. 이는 단일 스레드 환경에서는 괜찮지만, 삼각형들을 병렬로 계산하려고 할 때 코드가 깨지는 문제가 발생합니다. 여러 삼각형이 동일한 정점을 공유할 수 있기 때문입니다. 이는 결국 결과 탄젠트를 저장할 때 여러 다른 스레드에서 동일한 정점에 쓰기를 시도하게 되는데, 이것은 아주 큰 문제입니다. 이 방법의 문제는 아래에서 볼 수 있습니다:
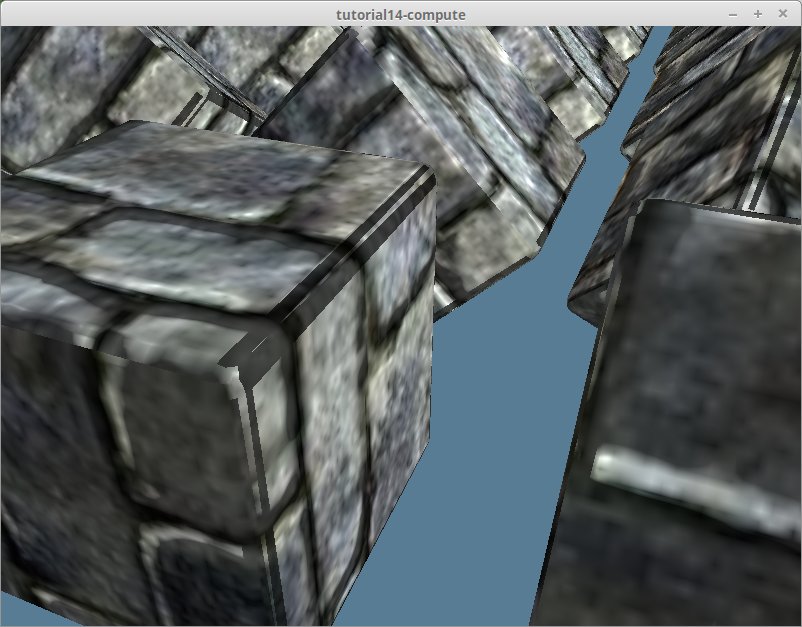
저 검은 삼각형들은 여러 GPU 스레드가 동일한 정점을 수정하려고 시도한 결과입니다. Render Doc으로 데이터를 확인해보니 탄젠트와 바이탄젠트 값이 NaN과 같은 쓰레기 값으로 채워져 있었습니다.
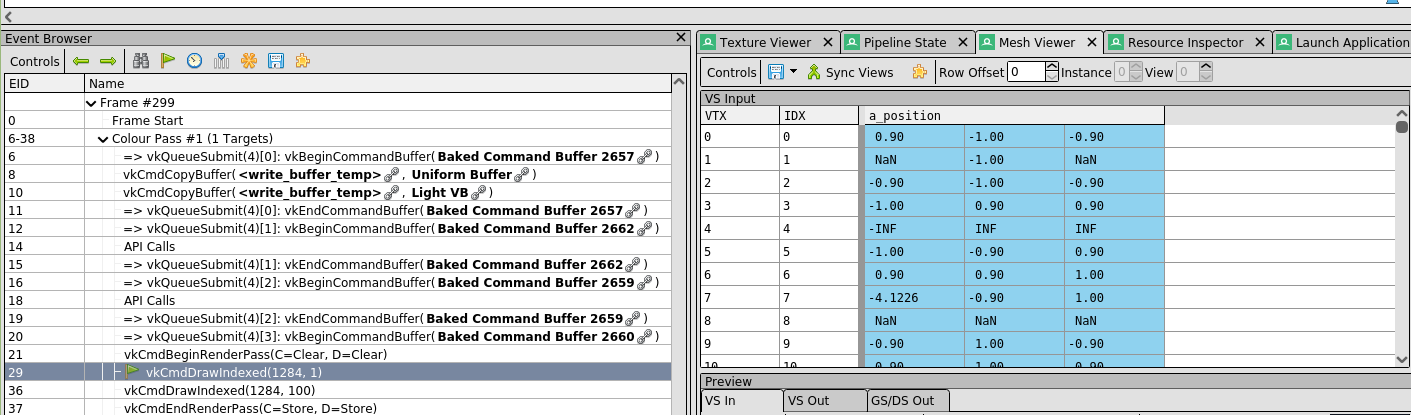
CPU에서는 Mutex와 같은 동기화 기본 요소를 도입하여 이 문제를 해결할 수 있지만, 제가 아는 한 GPU에는 그런 것이 거의 없습니다. 대신, 저는 각 정점을 개별적으로 처리하도록 코드를 변경하기로 결정했습니다. 여기에도 몇 가지 난관이 있지만, 코드를 통해 설명하는 것이 더 쉬울 것입니다. main 함수부터 시작하겠습니다.
void main() {
uint vertexIndex = gl_GlobalInvocationID.x;
ModelVertex result = calcTangentBitangent(vertexIndex);
dstVertices[vertexIndex] = result;
}
우리는 gl_GlobalInvocationID.x를 사용하여 탄젠트를 계산할 정점의 인덱스를 얻습니다. 실제 계산은 별도의 메서드로 분리했습니다. 그 메서드를 살펴보겠습니다.
ModelVertex calcTangentBitangent(uint vertexIndex) {
ModelVertex v = srcVertices[vertexIndex];
vec3 tangent = vec3(0);
vec3 bitangent = vec3(0);
uint trianglesIncluded = 0;
// v를 사용하는 삼각형 찾기
// * 모든 삼각형을 순회 (i + 3)
for (uint i = 0; i < numIndices; i += 3) {
uint index0 = indices[i];
uint index1 = indices[i+1];
uint index2 = indices[i+2];
// 인덱스 중 하나가 우리 vertexIndex와 일치할 경우에만
// 계산 수행
if (index0 == vertexIndex || index1 == vertexIndex || index2 == vertexIndex) {
ModelVertex v0 = srcVertices[index0];
ModelVertex v1 = srcVertices[index1];
ModelVertex v2 = srcVertices[index2];
vec3 pos0 = getPos(v0);
vec3 pos1 = getPos(v1);
vec3 pos2 = getPos(v2);
vec2 uv0 = getUV(v0);
vec2 uv1 = getUV(v1);
vec2 uv2 = getUV(v2);
vec3 delta_pos1 = pos1 - pos0;
vec3 delta_pos2 = pos2 - pos0;
vec2 delta_uv1 = uv1 - uv0;
vec2 delta_uv2 = uv2 - uv0;
float r = 1.0 / (delta_uv1.x * delta_uv2.y - delta_uv1.y * delta_uv2.x);
tangent += (delta_pos1 * delta_uv2.y - delta_pos2 * delta_uv1.y) * r;
bitangent += (delta_pos2 * delta_uv1.x - delta_pos1 * delta_uv2.x) * r;
trianglesIncluded += 1;
}
}
// 탄젠트와 바이탄젠트의 평균 계산
if (trianglesIncluded > 0) {
tangent /= trianglesIncluded;
bitangent /= trianglesIncluded;
tangent = normalize(tangent);
bitangent = normalize(bitangent);
}
// 결과 저장
v.tx = tangent.x;
v.ty = tangent.y;
v.tz = tangent.z;
v.bx = bitangent.x;
v.by = bitangent.y;
v.bz = bitangent.z;
return v;
}
# 개선 가능성
모든 정점에 대해 모든 삼각형을 순회하는 것은 일부 분들에게는 위험 신호로 보일 수 있습니다. 단일 스레드 환경에서 이 알고리즘은 O(N*M)이 될 것입니다. GPU에서 사용 가능한 수많은 스레드를 활용하고 있으므로 이는 큰 문제가 아니지만, 여전히 GPU가 필요 이상으로 많은 사이클을 소모하고 있다는 의미이기도 합니다.
성능을 개선하기 위해 제가 생각해 낸 한 가지 방법은 각 삼각형의 인덱스를 정점 인덱스를 키로 하는 해시 맵과 유사한 구조에 저장하는 것입니다. 다음은 의사 코드(pseudo code)입니다:
for t in 0..indices.len() / 3 {
triangle_map[indices[t * 3]].push(t);
triangle_map.push((indices[t * 3 + 1], t);
triangle_map.push((indices[t * 3 + 2], t);
}
그런 다음 이 구조체를 GPU에 전달하기 위해 펼쳐야 합니다. 첫 번째 배열을 인덱싱하기 위한 두 번째 배열도 필요할 것입니다.
for (i, (_v, t_list)) in triangle_map.iter().enumerate() {
triangle_map_indices.push(TriangleMapIndex {
start: i,
len: t_list.len(),
});
flat_triangle_map.extend(t_list);
}
저는 이 방법이 더 복잡하고, 단순한 방법보다 빠른지 벤치마킹할 시간이 없었기 때문에 최종적으로는 사용하지 않기로 결정했습니다.
# 결과
이제 탄젠트와 바이탄젠트가 GPU 상에서 올바르게 계산됩니다!